Introduction: Generative Models
Given observed samples from a distribution of interest, the goal of the generative model is to learn to model its true data distribution
. Once learned, we can generate new samples from our approximate model at will. Furthermore, under some formulations, we are able to use the learned model to evaluate the likelihood of observed or sampled data as well.
Background: ELBO, VAE, and Hierarchical VAE
Evidence Lower Bound
Mathematically, we can imagine the latent variables and the data we observe as modeled by a joint distribution . Recall one approach of generative modeling, termed “likelihood-based”, is to learn a model to maximize the likelihood
of all observed
. There are two ways we can manipulate this joint distribution to recover the likelihood of purely our observed data
; we can explicitly marginalize out the latent
variable
.
Denote is a flexible approximate variational distribution with parameters
that we seek to optimize.
From this derivation, we clearly observe that the evidence is equal to the ELBO plus the KL Divergence between the approximate posterior and the true posterior
.
Variational Autoencoders
In the default formulation of the Variational Autoencoder (VAE), we directly maximize the ELBO. This approach is variational, because we optimize for the best amongst a family of potential posterior distributions parameterized by
.
In this case, we learn an intermediate bottlenecking distribution that can be treated as an encoder; it transforms inputs into a distribution over possible latents. Simultaneously, we learn a deterministic function
to convert a given latent vector
into an observation
, which can be interpreted as a decoder.
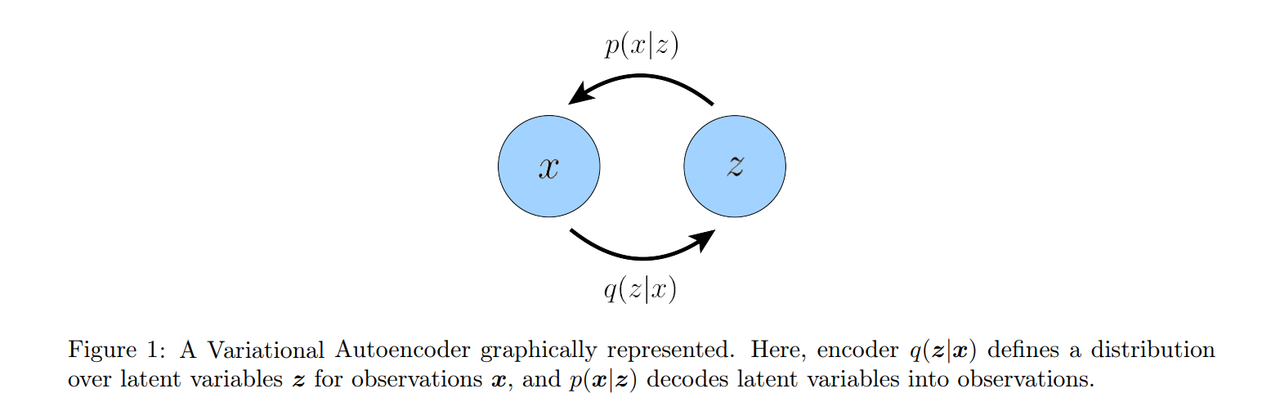
Hierarchical Variational Autoencoders
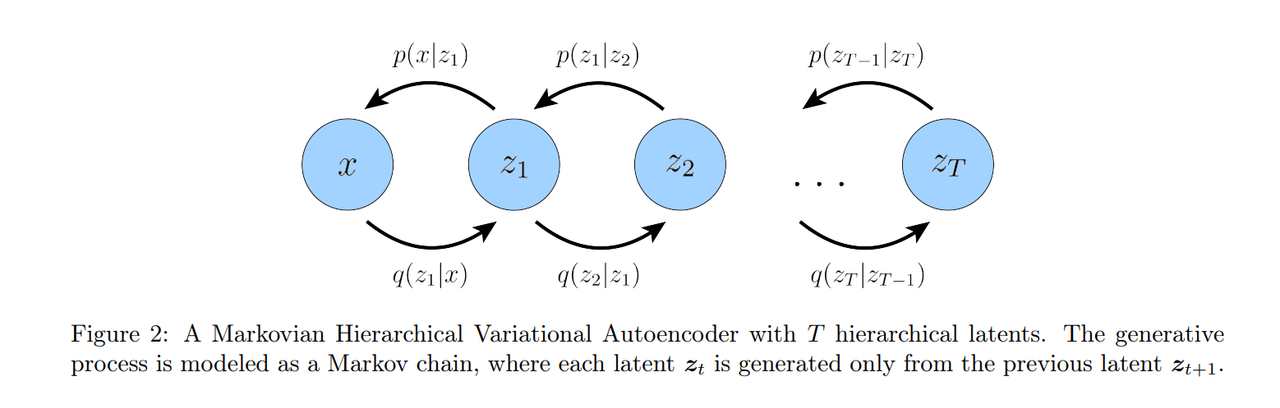
A Hierarchical Variational Autoencoder (HVAE) is a generalization of a VAE that extends to multiple hierarchies over latent variables. Under this formulation, latent variables themselves are interpreted as generated from other higher-level, more abstract latents.
Whereas in the general HVAE with T hierarchical levels, each latent is allowed to condition on all previous
latents, in this work we focus on a special case which we call a Markovian HVAE (MHVAE). In a MHVAE, the generative process is a Markov chain; that is, each transition down the hierarchy is Markovian, where decoding each latent only conditions on previous latent
.
Intuitively, and visually, this can be seen
as simply stacking VAEs on top of each other, as depicted in Figure 2; another appropriate term describing this model is a Recursive VAE. Mathematically, we represent the joint distribution and the posterior of a
Markovian HVAE as:
Then, we can easily extend the ELBO to be:
Variational Diffusion Models
The easiest way to think of a Variational Diffusion Model (VDM is simply as a Markovian Hierarchical Variational Autoencoder with three key restrictions:
- The latent dimension is exactly equal to the data dimension.
- The structure of the latent encoder at each timestep is not learned; it is pre-defined as a linear Gaussian model. In other words, it is a Gaussian distribution centered around the output of the previous timestep.
- The Gaussian parameters of the latent encoders vary over time in such a way that the distribution of the latent at final timestep T is a standard Gaussian.
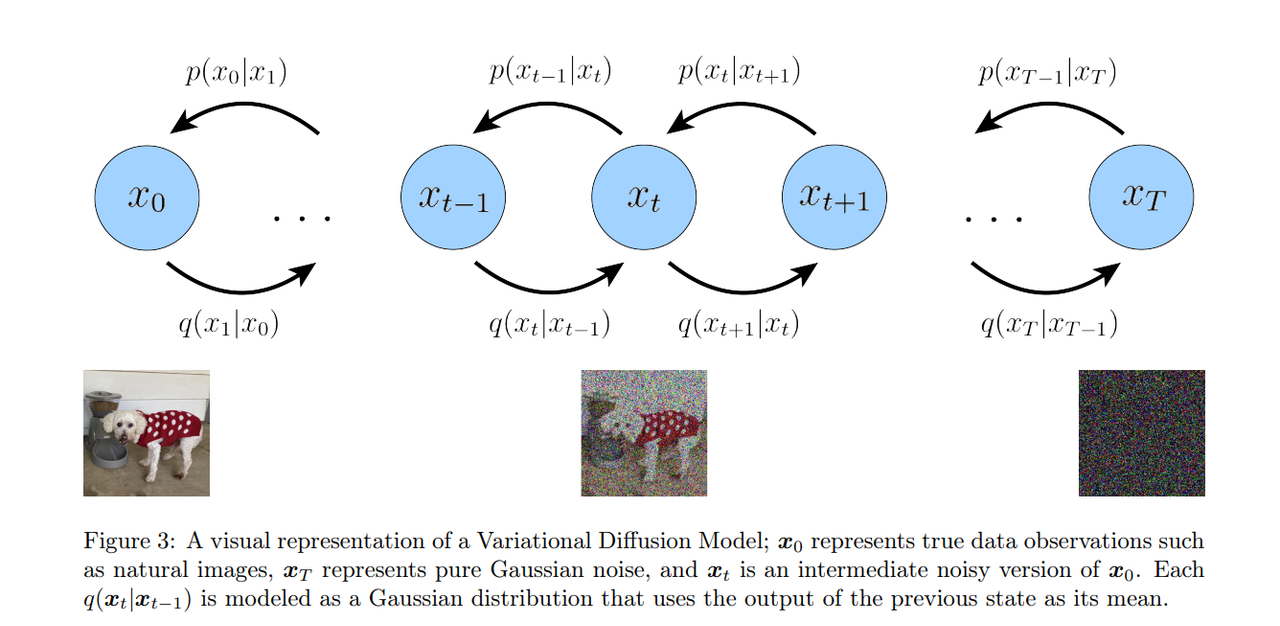
The VDM posterior is the same as the MHVAE posterior, but can now be rewritten as:
From the second assumption, we know that the distribution of each latent variable in the encoder is a Gaussian centered around its previous hierarchical latent. Unlike a Markovian HVAE, the structure of the
encoder at each timestep t is not learned; it is fixed as a linear Gaussian model.
We parameterize the Gaussian encoder with mean and variance
, where the form of the coefficients are chosen such that the variance of the latent variables stay at a similar scale; in other words, the encoding process is variance-preserving. Mathematically, encoder transitions are denoted as:
The joint distribution for a VDM as:
where
Like any HVAE, the VDM can be optimized by maximizing the ELBO, which can be derived as:
The derived form of the ELBO can be interpreted in terms of its individual components:
can be interpreted as a reconstruction term, predicting the log probability of the original data sample given the first-step latent. This term also appears in a vanilla VAE, and can be trained similarly.
is a prior matching term; it is minimized when the final latent distribution matches the Gaussian prior. This term requires no optimization, as it has no trainable parameters; furthermore, as we have assumed a large enough T such that the final distribution is Gaussian, this term effectively becomes zero.
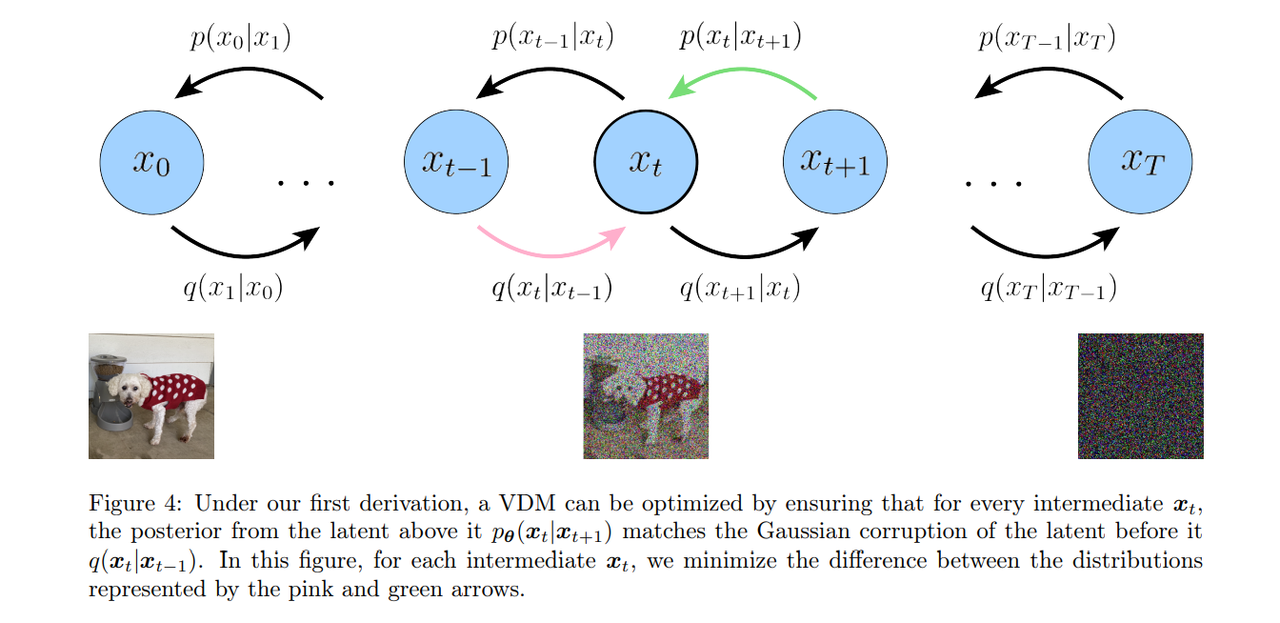
is a consistency term; it endeavors to make the distribution at
consistent, from both forward and backward processes. That is, a denoising step from a noisier image should match the corresponding noising step from a cleaner image, for every intermediate timestep; this is reflected mathematically by the KL Divergence. This term is minimized when we train
to match the Gaussian distribution
.
We can rewrite encoder transitions as . Then, according to Bayes rule, we can rewrite each transition as:
Armed with this new equation, we can retry the derivation resuming from the ELBO:
We have therefore successfully derived an interpretation for the ELBO that can be estimated with lower variance, as each term is computed as an expectation of at most one random variable at a time. This formulation also has an elegant interpretation, which is revealed when inspecting each individual term:
can be interpreted as a reconstruction term; like its analogue in the ELBO of a vanilla VAE, this term can be approximated and optimized using a Monte Carlo estimate.
represents how close the distribution of the final noisified input is to the standard Gaussian prior. It has no trainable parameters, and is also equal to zero under our assumptions.
is a denoising matching term. We learn desired denoising transition step
as an approximation to tractable, ground-truth denoising transition step
. The
transition step can act as a ground-truth signal, since it defines how to denoise a noisy image
should be. This term is therefore minimized when the two denoising steps match as closely as possible, as measured by their KL Divergence.
We have:
As we already know that from our assumption regarding encoder transitions, what remains is deriving for the forms of
and
. Fortunately, these are also made tractable by utilizing the fact that the encoder transitions of a VDM are linear Gaussian models.
Recall that under the reparameterization trick, samples can be rewritten as:
with
and that similarly, samples can be rewritten as:
with

Then, the form of can be recursively derived through repeated applications of the reparameterization
trick. Suppose that we have access to
random noise variables
. Then, for an arbitrary sample
, we can rewrite it as:
We have therefore derived the Gaussian form of . This derivation can be modified to also yield the
Gaussian parameterization describing
. Now, knowing the forms of both
and
, we can proceed to calculate the form of
by substituting into the Bayes rule expansion:
We have therefore shown that at each step, is normally distributed, with mean
that is a function of
and
, and variance
as a function of
coefficients.
In order to match approximate denoising transition step to ground-truth denoising transition step
as closely as possible, we can also model it as a Gaussian. Furthermore, as all
terms are known to be frozen at each timestep, we can immediately construct the variance of the approximate
denoising transition step to also be
.
Recall that the KL divergence between two Gaussian distribution is:
In our case, where we can set the variances of the two Gaussians to match exactly, optimizing the KL Divergence term reduces to minimizing the difference between the means of the two distributions:
where we have written as shorthand for
, and
as shorthand for
for brevity. In
other words, we want to optimize a
that matches
,
As also conditions on
, we can match
closely by setting it to the following form:
where is parameterized by a neural network that seeks to predict
from noisy image
and time
index
. Then, the optimization problem simplifies to:
Therefore, optimizing a VDM boils down to learning a neural network to predict the original ground truth image from an arbitrarily noisified version of it.
Three Equivalent Interpretations
As we previously proved, a Variational Diffusion Model can be trained by simply learning a neural network to predict the original natural image from an arbitrary noised version
and its time index
. However,
has two other equivalent parameterizations, which leads to two further interpretations for a VDM.
We have
Plugging this into our previously derived true denoising transition mean , we can rederive as:
Therefore, we can set our approximate denoising transition mean as:
and the corresponding optimization problem becomes:
Here, is a neural network that learns to predict the source noise
that determines
from
. We have therefore shown that learning a VDM by predicting the original image
is equivalent to
learning to predict the noise.
References
- Lil’Log, What are Diffusion Models?, Link
- Calvin Luo, Understanding Diffusion Models: A Unified Perspective