- Trong bài viết này chúng ta sẽ đề cập đến một lớp các thuật toán được gọi là Bound Optimization hoặc MM Optimization. Trong ngữ cảnh minimization, MM được hiểu là Majorize-Minimize, trong ngữ cảnh maximization, MM được hiểu là Majorize-Maximize. Chúng ta sẽ nói về một trường hợp đặc biệt của MM là Expectation Maximization hoặc EM.
I. Định nghĩa - Giả sử mục tiệu là maximize hàm
, chẳng hạn như hàm log likelihood với tham số
. Cách tiếp cận cơ bản trong MM là đi xây dựng surrogate function
là một chặn dưới của
và
. Nếu các điều kiện này thỏa mãn, ta gọi
minorizes
.
Sau đó thực hiện cập nhật sau mỗi bước:
Điều này đảm bảo sự đơn điệu tăng trong hàm mục tiêu ban đầu.
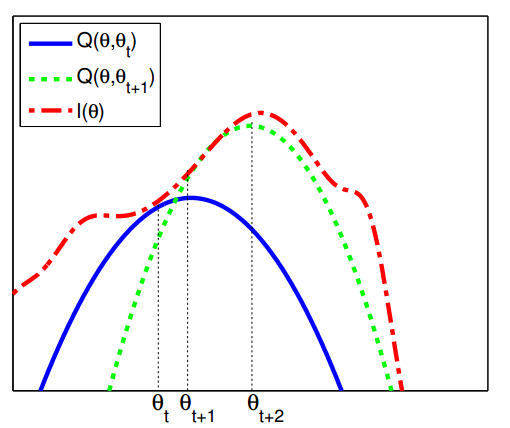
Minh họa Bound Optimization: Đường nét đứt màu đỏ là hàm mục tiêu gốc, đường nét liền màu xanh là lower bound tại vị trí, nó tiếp xúc với hàm objective gốc tại vị trí
. Đường nét đứt màu xanh tiếp xúc với hàm mục tiêu gốc tại
.
II. Thuật toán Expectation Maximization (EM)
- EM là thuật toán để tính MLE (Maximum Likelihood Estimation) hoặc MAP parameter estimate cho probability models mà có dữ liệu không đầy đủ (missing data) hoặc có biến ẩn (hidden variables).
“A general technique for finding maximum likelihood estimators in latent variable models is the expectation-maximization (EM) algorithm.”
Page 424, Pattern Recognition and Machine Learning, 2006.
“… if we have missing data and/or latent variables, then computing the [maximum likelihood] estimate becomes hard.”
Page 349, Machine Learning: A Probabilistic Perspective, 2012 - EM gồm 2 bước chính:
- E step (Expectation step): Estimate the missing variables in the dataset.
- M step (Maximization step): Maximize the parameters of the model in the presence of the data.
- Một số ứng dụng của EM như fit mixture models (such as Gaussian mixture model), fit a multivariate Gaussian (khi missing data), fit robust linear regression models,…
1. Lower bound
-
Mục tiêu của thuật toán EM là maximize log likelihood của dữ liệu quan sát được (observed data):
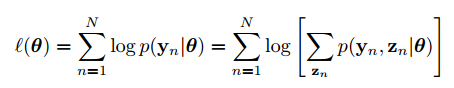
trong đó
là dữ liệu quan sát được (visible variables) còn
là dũ liệu ẩn (visible variables).
Xét một tập hợp các phân phối tùy ý (arbitrary distributions)đối với mỗi biến ẩn
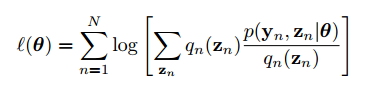
Nhắc lại bất đẳng thức Jensen (Jensen’s inequality): Với hàm lồi (convex function)
, ta có:
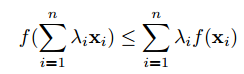
với
và
.
Đối với hàm lõm (concave function) thì ta đổithành
. Ví dụ với hàm
là hàm lõm ta có
.
Sử dụng BĐT Jensen ta có:
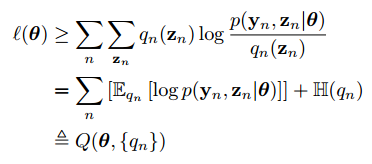
trong đó
là phân phối xác suất của
:
Biểu thức
Thuật toán EM sẽ luân phiên việc tối đa lower boundvà tham số
2. E step
-
Ta có:
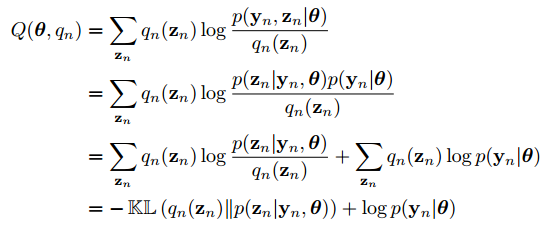
trong đó
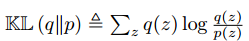
là Kullback-Leibler divergence giữa 2 phân phối xác suấtvà
và
.
DO đó ta có thể maximize lower boundwrt
. Khi đó ta có:
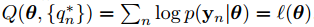
3. M step
-
Trong M step, ta cần maximize
wrt
được tính ở E step ở iteration t. Do
là hằng số đối với
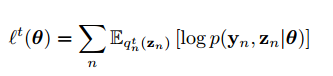
Biểu thức này được gọi là expected complete data log likelihood. Ta sẽ maximize hàm này để thu được
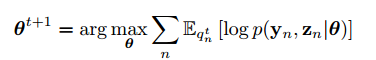
Tóm lại, thuật toán EM được viết dạng mã giả như sau (
: mẫu dữ liệu, thông tin về
bị ẩn).

Về ứng dụng của EM mình sẽ trình bày ở các bài tiếp theo.
III. Tài liệu tham khảo
1. Probabilistic Machine Learning: An Introduction, by Kevin Patrick Murphy. MIT Press, 2021. https://probml.github.io/pml-book/book1.html 2. http://uet.vnu.edu.vn/~tqlong/2016hmtk/em.pdf 3. https://machinelearningmastery.com/expectation-maximization-em-algorithm/