Ở các bài trước, chúng ta sử dụng gradient descent với miền của là
. Khi miền
thì điểm cập nhật mới
có thể không thuộc
. Do đó sau mỗi bước cập nhật ta phải chiếu nó xuống
để thu được điểm thuộc
. Đây là một bài toán tối ưu có ràng buộc (constrained optimzation).

Trong bài này mình sẽ trình bày về Projected Gradient Descent.
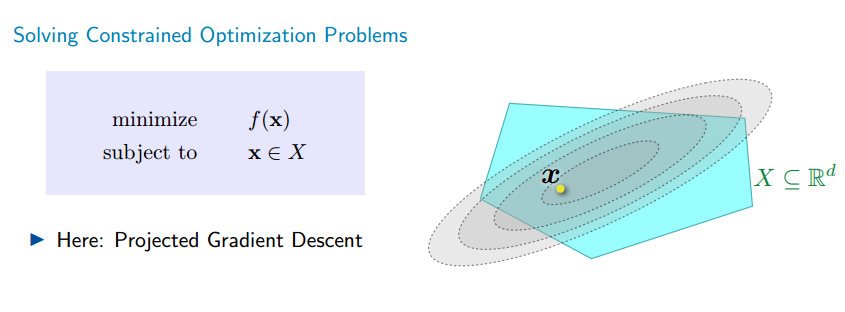
Sau mỗi lần cập nhật, thuật toán sẽ chiếu điểm xuống miền .

Ta có công thức cập nhật của projected gradient descent như sau:
Trước hết ta có một số tính chất sau:
Cho là tập đóng và lồi. Cho
. Khi đó
i))
ii))
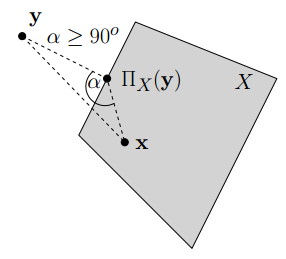
Chứng minh
Ta có bổ đề quan trọng sau:
Bổ đề: Cho hàm là hàm lồi và khả vi trên toàn miền
và cho
là tập lồi. Điểm
được gọi là minimizer của
trên toàn miền
nếu và chỉ nếu
với mọi
.
i) Dễ thấy là minimizer của hàm lồi
trên miền
. Sử dụng bổ đề trên ta có:
(đpcm)
ii) Đặt . Sử dụng i) ta có
.
Suy ra (đpcm)
Việc phân tích tính hội tụ của Projected Gradient Descent trên các dạng hàm Lipschitz Convex Function, Smooth Convex Function, Smooth and Strongly Convex Function hoàn toàn tương tự ở các bài trước về Gradient Descent.
Tài liệu tham khảo
- https://github.com/epfml/OptML_course
- https://ee227c.github.io/
- Stephen Boyd and Lieven Vandenberghe.
Convex Optimization.
Cambridge University Press, New York, NY, USA, 2004.