- Ở bài cuối của chuỗi bài phân tích tính hội tụ của thuật toán Gradient Descent mình sẽ phân tích đối với hàm smooth và strongly convex function. Đây là 2 tính chất quan trọng kết hợp trong 1 hàm làm cho thuật toán gradient descent “faster”.
- Định nghĩa: Cho hàm
là hàm lồi và khả vi,
lồi và
. Hàm
được gọi là strongly convex (với parameter
) trên
nếu
,
.
Nếuthì
Hàm smooth convex đã được định nghĩa ở bài trước.
Dễ thấy rằng mọi hàm lồi đều thỏa mãn tính chất trên với.
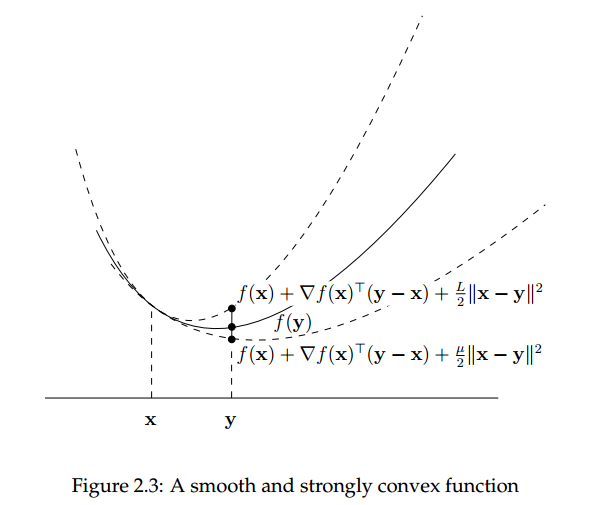
Ta có một số tính chất quan trọng sau của strongly convex function.
- Bổ đề 1: Nếu hàm
strongly convex với tham số
thì
-
Bổ đề 2: Cho
. Khi đó
với
.
Ta có.
SỬ dụng biểu thức phần tích bài ở phần 1 và tính chất của strongly convex function
.
Ta được
(1)
Suy ra(2)
- Định lý: Cho hàm
và strongly convex với tham số
.
gradient descent với điểm bắt đầubất kì ta có
i),
.
ii) Gọilà số vòng lặp tại một thời điểm nào đó.
.
Chứng minh
i) Sử dụng định lý ở bài Phần 2 ta có .
Mà nên ta được
.
Từ 1) suy ra (đpcm).
i)) Do smooth và
nên
.
Suy ra đpcm.
Từ đây cũng suy ra được , hay số iteration khoảng
.
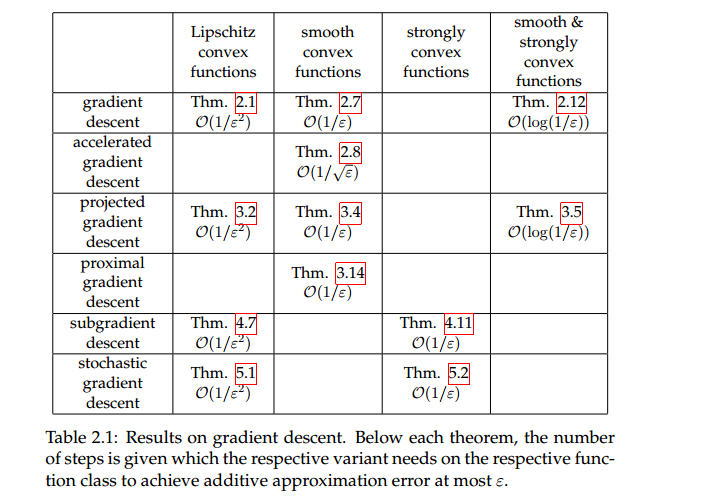
Bảng tổng kết
Tài liệu tham khảo
- https://machinelearningcoban.com/
- https://github.com/epfml/OptML_course
- https://ee227c.github.io/
- Stephen Boyd and Lieven Vandenberghe.
Convex Optimization.
Cambridge University Press, New York, NY, USA, 2004. - https://easyai.tech/en/ai-definition/gradient-descent/
- https://towardsdatascience.com/binary-cross-entropy-and-logistic-regression-bf7098e75559?fbclid=IwAR1kSrG7pKJQvmge-M14CUkhjsZ0nlFA1Tw_4tBDWnBkBP8_fblXLrylk3s
- http://www.seas.ucla.edu/~vandenbe/236C/lectures/gradient.pdf