- Ở bài trước mình đã phân tính tính hội tụ của Gradient Descent đối với hàm Lipschitz Convex Function. Số steps khoảng
.
-
Bài viết này mình sẽ phân tích tính hội tụ của Gradient Descent với dạng hàm Smooth Convex Function.
(Có thể hình dung hàm này là “Not too curved”)
Nhắc lại tính chất first-order characterization of convexity của hàm lồi:
Với mọita có
.
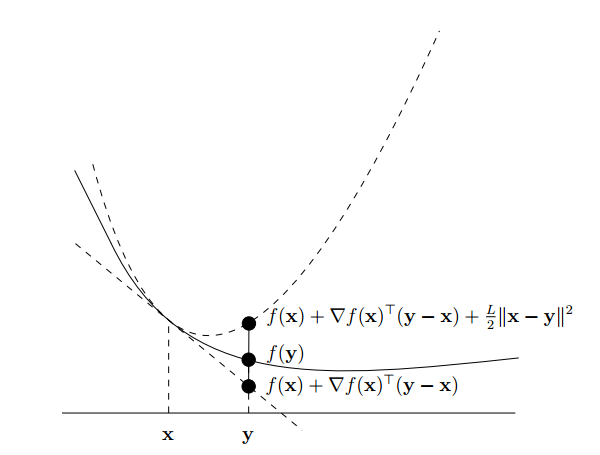
Định nghĩa [smooth]: Cho hàm sốlà hàm khả vi,
và
. Hàm
được gọi là “trơn” (smooth) (với tham số
) trên
nếu
với mọi
.
Định nghĩa [smooth convex]: Cho hàm số
- Với trường hợp
thì ta có
(do kết hợp với tính chất first-order characterization of convexity của hàm lồi) suy ra
Lấy ví dụ với hàmlà hàm lồi và dễ thấy rằng
với
. Do vậy hàm
Hình sau minh họa hàm smooth convex.
Tổng quát hơn xét hàm bậc hai một biến với
cũng là một hàm smooth convex với
.
Có thể tự kiểm chứng với với
.
Còn với biến là một vector, dạng toàn phương (quadratic form) có dạng
với
là ma trận đối xứng và nửa xác định dương thì hàm này có phải là hàm smooth convex không? Câu trả lời là có.
Ta có định lý sau:
Định lý: Cho hàm trong đó
là ma trận nửa xác định dương, đối xứng,
. Khi đó
smooth convex với tham số
, trong đó
là spectral norm của
.
Về spectral norm của ma trận được định nghĩa như sau:
Định nghĩa [spectral norm of matrix]. Cho ma trận . Khi đó
được gọi là hay spectral norm của
.
Lưu ý: spectral norm này khác với Frobenius norm của ma trận.
Chứng minh
Do là ma trận đối xứng, nửa xác định dương nên
là hàm lồi. Hơn nữa ta cũng có
với
bất kỳ. Khi đó có thể viết lại
Sử dụng bất đẳng thức Cauchy-Schwarz và tính chất của spectral norm ta có
Suy ra . Mà
. Do đó
. Điều này chứng tỏ
smooth với tham số
Tiếp theo là một định lý về hàm smooth convex.
Định lý: Cho là hàm lồi, khả vi. Hai mệnh đề sau là tương đương.
i) smooth với tham số
.
ii) với mọi
.
Chứng minh:
Sử dụng tính chất của tập lồi, xét thì
cũng thuộc
với
.
Xét hàm . Giả sử ta có ii) thì ta có:
Lấy tích phân từ đến
ta có:
.
Từ đây suy ra smooth convex với tham số
.
Ngược lại nếu ta có i) tức là .
Hoán đổi ta được
.
Từ đây dễ dàng suy ra .
Như vậy i) và i)) tương đương nhau.
Định lý: Cho hàm khả vi và trơn với tham số
. Với learning rate
khi áp dụng thuật toán gradient descent ta có
,
Chứng minh
Với learning rate thì theo công thức cập nhật của gradient descent ta có
và áp dụng công thức hàm trơn:
Sau đây là định lý về sự hội tụ của gradient descent với hàm smooth convex.
Định lý: Cho hàm lồi, khả vi với điểm global minimum là
, giả sử
trơn với tham số
. Với learning rate
khi áp dụng gradient descent ta có:
,
Chứng minh
Áp dụng định lý trên và lấy tổng từ ta có
.
Với và áp dụng phân tích đã có trong bài Về tính hội tụ của thuật toán Gradient Descent (Phần 1) ta có:
hay
.
Mặc khác do với
nên
.
Giả sử khoảng cách giữa điểm khởi tạo và điểm global minimum là , tức là
. Khi đó ta cần
để khoảng cách error là
.
Ta thấy số vòng lặp ít nhất phụ thuộc vào cả và
.
Từ đây ta ước lượng số vòng lặp với hàm smooth convex khoảng . Nhanh hơn so với hàm Lipschitz convex.
Đặc biệt với hàm hay tổng quát hơn
là hàm smooth convex với tham số
nên nếu chọn learning rate là
thì chỉ cần sau một vòng lặp thì gradient descent đã hội tụ đúng điểm tối ưu. Vì khi đó với
thì
.
Tài liệu tham khảo
- https://machinelearningcoban.com/
- https://github.com/epfml/OptML_course
- https://ee227c.github.io/
- Stephen Boyd and Lieven Vandenberghe.
Convex Optimization.
Cambridge University Press, New York, NY, USA, 2004. - https://easyai.tech/en/ai-definition/gradient-descent/
- https://towardsdatascience.com/binary-cross-entropy-and-logistic-regression-bf7098e75559?fbclid=IwAR1kSrG7pKJQvmge-M14CUkhjsZ0nlFA1Tw_4tBDWnBkBP8_fblXLrylk3s
- http://www.seas.ucla.edu/~vandenbe/236C/lectures/gradient.pdf