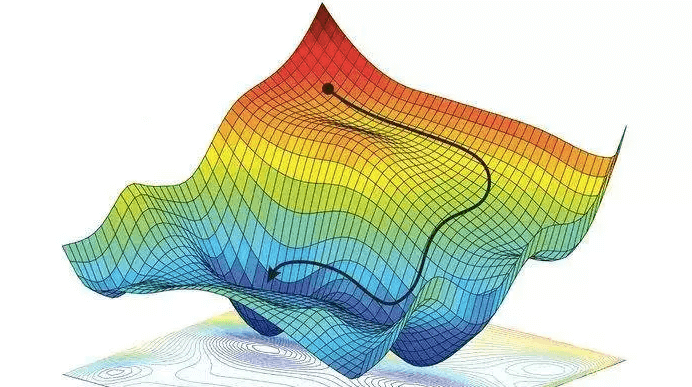
- Trong bài toán tối ưu cụ thể là các bài toán tìm giá trị lớn nhất hay giá trị nhỏ nhất của một hàm số, ta thường đi giải phương trình đạo hàm hoặc đạo hàm riêng bằng 0 đối với hàm nhiều biến. Tuy nhiên, việc tối ưu hàm lỗi trong Machine Learning gặp phải các vấn đề sau:
- Với những tập dữ liệu lớn, nhiều chiều thì sẽ gây ra tốn bộ nhớ của máy tính và tính toán chậm chạp. Ví dụ công thức tính tham số của thuật toán Linear Regression như sau
(kí hiệu
là ma trận giả nghịch đảo). Khi đó nếu dữ liệu train lớn và chiều của dữ liệu lớn thì kích thước ma trận
sẽ lớn, việc tính nghịch đảo và nhân ma trận sẽ chậm.
- Trong nhiều thuật toán Machine Learning các hàm lỗi (Loss Function) đôi khi rất phức tạp nên việc tính đạo hàm là không khả thi.
Và thuật toán Gradient Descent sẽ giải quyết hai vấn đề nêu trên.
- Với những tập dữ liệu lớn, nhiều chiều thì sẽ gây ra tốn bộ nhớ của máy tính và tính toán chậm chạp. Ví dụ công thức tính tham số của thuật toán Linear Regression như sau
- Ý tưởng của Gradient Descent là giá trị hàm số sẽ giảm nhanh nhất khi đi ngược hướng đạo hàm.
Công thức cập nhật trọng số:với
là tham số mô hình và
gọi là tốc độ học (learning rate).
Chi tiết rõ hơn về thuật toán, các biến thể và cách cài đặt có thể xem tại Blog Machine Learning cơ bản - Ở bài này mình sẽ phân tích tính hội tụ của Gradient Descent, số lần lặp tối thiểu để thuật toán hội tụ và tốc độ hội tụ của từng dạng hàm số (các hàm được đề cập đều có tính chất chung là hàm lồi). Trước tiên ta đi qua một số kiến thức chuẩn bị.
I. Một số kiến thức chuẩn bị
1. Lý thuyết về tập lồi, hàm lồi
- Một tập
được gọi là tập lồi nếu mọi điểm trên đoạn thẳng nối 2 điểm bất kỳ trong tập
và với
ta có
.
- Ví dụ tập lồi
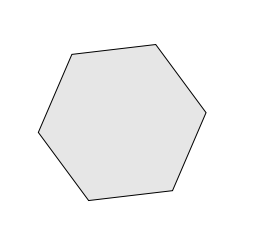
- Ví dụ tập không lồi
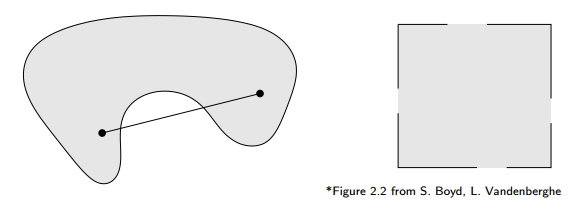
- Một hàm
được gọi là hàm lồi nếu miền xác định của
,
là một tập lồi và với mọi
và
ta có
.
Một cách hình học: Đoạn thẳng nối giữanằm trên đồ thị của
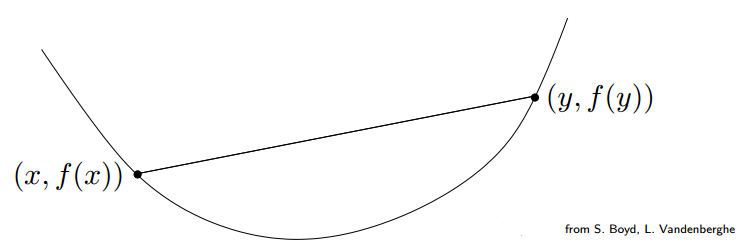
- [Hàm lồi chặt - Strictly Convex Function]. Hàm
là hàm lồi chặt nếu
và với mọi
, ta có
- Một số hàm lồi
- Linear functions:
- Affine functions:
- Exponential:
- Norms: Mọi norm trên
đều là hàm lồi.
Ví dụ xét tính lồi của. Sử dụng tính chất của norm là bất đẳng thức tam giác
và
với
là số thực.
Ta có. Do vậy norm là một hàm lồi.
- Linear functions:
2. Kiểm tra tính chất lồi dựa vào đạo hàm bậc nhất (First-order characterization of convexity)
- Định lý: Giả sử hàm số
tồn tại với mọi
. Khi đó hàm
với mọi
Một cách trực quan: Hàm số là lồi nếu mặt tiếp tuyến tại một điểm bất kỳ trên đồ thị hàm số không nằm trên đồ thị đó.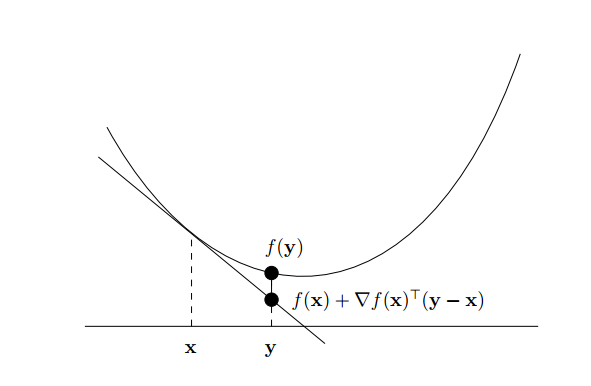
3. Kiểm tra tính chất lồi dựa vào đạo hàm bậc hai (Second-order characterization of convexity)
- Hàm
có đạo hàm (differentiable) và
liên tục (continuous).
- Định lý: Giả sử hàm số
của
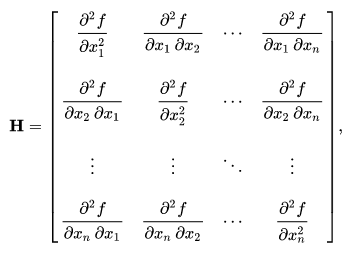
là ma trận đối xứng và tồn tại với mọi. Khi đó
, hay
4. Local Minimum và Global Minimum
- Vấn đề của Gradient Descent là nó chỉ tìm được một điểm cực tiểu local minimum và ta không biết được điểm đó có phải là global minimum hay không. Tuy nhiên có một tính chất qua trọng sau: Nếu hàm số đó làm hàm lồi (convex) thì local minimum đó cũng chính là global minimum, tính chất này sẽ chứng minh sau đây.
- Định nghĩa: Một local minimum (điểm tối ưu cục bộ) của hàm
sao cho tồn tại
với
với mọi
thỏa mãn
.
- Định lý: Gọi
là local minimum của hàm lồi
với mọi
Chứng minh: Giả sử rằng tồn tại.
Đặtvới
Từ tính chất của hàm lồi ta có:
Do đó. Chọn
càng gần 1 thì
. Điều này mẫu thuẫn với
Từ đây suy ra điều phải chứng minh.
Để ý thấy hàm Mean Square Error (MSE) trong Linear Regression hay Cross Entropy trong Logistic Regression đều là các hàm lồi. Các bạn có thể tự kiểm chứng điều này hoặc xem tại Binary cross-entropy and logistic regression. Khi đó dùng thuật toán tối ưu Gradient Descent thì sẽ tìm được điểm tối ưu toàn cục.
Thường các hàm lỗi trong Deep Neural Network là các hàm non-convex và đây là vấn đề của Non-convex Optimization. - Định lý: Cho
thì
- Định lý: Cho
II. Phân tích tính hội tụ của Gradient Descent
Cho hàm có đạo hàm và là hàm lồi. Giả sử rằng
có điểm global minimum
và mục tiêu là đi tìm (hoặc xấp xỉ)
, nghĩa là với
cho trước, ta cần tìm
sao cho
.
Nhắc lại công thức cập nhật của Gradient Descent hay viết lại
. Chúng ta muốn tìm số vòng lặp
(số lần cập nhật) nhỏ nhất mà thỏa mãn
.
Phần đầu tiên chúng ta tiếp cận với hàm Lipschitz Convex Function
- Định nghĩa: (L-Lipschitz). Một hàm
được gọi là L-Lipschitz nếu với mọi
ta có
.
- Định lý: Nếu hàm
với mọi
.
- Định lý: Cho
là hàm lồi, có đạo hàm và L-Lipschitz trên toàn miền xác định của
(
là điểm khởi tạo ban đầu) và
với mọi
. Gọi
là dãy các giá trị
Khi đó ta có.
Chứng minh:
Đặt. Khi đó
.
Áp dụng công thứcvới
.
Ta có.
Lấy tổng trênlần cập nhật đầu tiên:
Sử dụng tính chất first-order characterization of convexity ta có:
.
Chọnta được
.
Khi đó.
Biểu thức này gọi là chặn trên của trung bình lỗitrên tất cả các lần cập nhật.
Dovà
nên
.
Xét hàm.
Ta chọnsao cho
đạt giá trị nhỏ nhất.
Giải phương trình đạo hàmđược
và
.
Từ đây dễ thấy vớithì average error
.
Và do.
Suy ra số lần cập nhật của Gradient Descent đối với hàm Lipschitz Convex Function là khoảngvới
bất kỳ cho trước.
Ở bài sau mình sẽ nói về tốc độ hội tụ của Gradient Descent trên các hàm Smooth Convex Function và Strongly Convex Function.
III. Tài liệu tham khảo
- https://machinelearningcoban.com/
- https://github.com/epfml/OptML_course
- https://ee227c.github.io/
- Stephen Boyd and Lieven Vandenberghe.
Convex Optimization.
Cambridge University Press, New York, NY, USA, 2004. - https://easyai.tech/en/ai-definition/gradient-descent/
- https://towardsdatascience.com/binary-cross-entropy-and-logistic-regression-bf7098e75559?fbclid=IwAR1kSrG7pKJQvmge-M14CUkhjsZ0nlFA1Tw_4tBDWnBkBP8_fblXLrylk3s